
第一环节 魔塔+阿里云跑通Baseline Demo
Task1的第一个环节就是让我使用阿里云提供的免费算力额度+便捷开发环境IDE,魔塔社区提供的大模型管理平台,以及浪潮信息提供的开源大预言模型,创建一个属于自己的、客户端在本地的而在云环境上运行的个人编程助手。
Datawhale给出的帮助手册,已经很详细地告诉我们每一步应该怎么做了。但是为了照顾新手,并没有解释其中涵盖的比较基础的知识点,这篇笔记,咱们就来对每一步做一个知识提取,为往后的大模型引用开发搭建一个牢固的知识基础。
阿里云PAI-DSW
阿里云PAI-DSW的英文全称是Platform as a Service Data Science Workshop,是一款云端机器学习开发IDE,基于阿里云Docker和Kubernetes等云原生技术的AI开发环境。它集成了开源JupyterLab,并以插件化的形式进行深度定制化开发。您无需任何运维配置,即可进行Notebook编写、调试及运行Python代码。每一个DSW,都是一个实例,都是一个独立的开发环境。
本次领取的PAI-DSW套餐
本次阿里云免费提供的DSW套餐,官网有写一些规格信息,为了方便以后理解,这里对每一项规格信息都做一个解释:
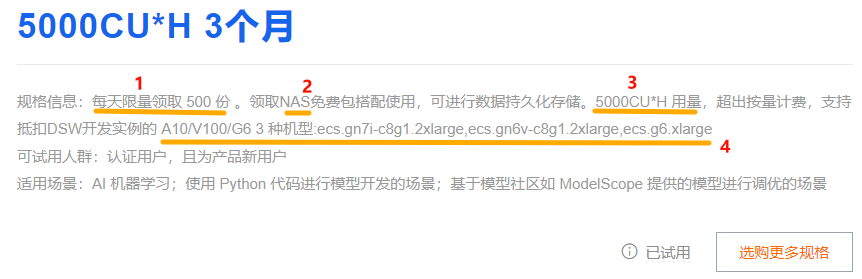
- 每天可以免费申请或领取的套餐数量是500份,意味着在一天之内,最多有500个用户或账户可以申请到这个特定的套餐。
- NAS:网络附加存储(Network Attached Storage),它允许用户将数据存储在云中的共享文件系统上。在与PAI-DSW的搭配使用当中,NAS所起的作用是,用户可以将数据持久化存储在NAS上,而不是仅在DSW实例的本地存储中,这样即使DSW实例停止运行或被销毁,数据也不会丢失。
- “CU*H”是计算单元(Compute Unit)乘以小时(hour)的计量单位,表示计算资源消耗的量度。
- A10、V100和G6是阿里云三种不同型号的DSW,分别代表了不同的GPU资源。
ecs.gn7i-c8g1.2xlarge和ecs.gn6v-c8g1.2xlarge通常代表了配备NVIDIA A10 GPU的实例。而ecs.g6.xlarge可能代表了配备NVIDIA V100或G6 GPU的实例,但通常G6指的是阿里云自研的GPU。
魔塔Modelscope社区
是一个国内的机器学习平台,主要聚焦于国内大模型、数据集和各类AI应用的共建共享。可以认为是huggingface的国内版。
创建PAI DSW实例
这里没有什么好说的,就是在一个工作空间下进行资源配额。
在DSW上尝试运行Demo
git lfs install这行命令旨在安装lfs扩展,使git更高效地处理大型文件。往后我们在huggingface上查看浪潮信息开源的Files and Version中将能看到,确实有俩显眼包,需要有LFS的协助才能下载下来。

pip install streamlit==1.24.0就是安装一个将streamlit的客户端,便于我们在美观的UI界面向远程的源大模型服务器发送请求并处理收到的响应。
最后就是每次使用玩记得关闭DSW实例,每小时都会消耗大概7个试用额度(总共5000个CU,有效期三个月)
遇到的问题
运行Demo时,遭遇LICENSE文件不存在的问题。

分析一下,当我去huggingface的源大模型2.0-2B官网去查看Files的时候,对比发现,我其实不止缺少LICENSE,还缺少诸多文件,没能下载到至DSW实例上。推测是最初配置DSW的问题,重新按照说明再创建了一个DSW,发现一切都正常了。
然而,求助群内同志的过程中,除了已知地直接从huggingface/modelscope官网或者对应的镜像网站git clone这一方案以外,还可以使用pip的降级安装来解决问题,但我还没有实践过:

大模型入门理论知识
大模型的定义和发展历程
大模型是指具有大量参数(通常是数亿甚至数千亿级别)的人工智能模型,它们通过深度学习技术进行训练,能够处理复杂的任务和大规模数据集。大模型的发展经历了从统计语言模型到神经语言模型,再到预训练语言模型,直至当前的大语言模型(LLM)阶段。这些模型通过学习语言的内在规律,能够生成连贯的文本输出,并在自然语言处理等领域展现出强大的能力。、

大模型的构建过程
大模型的构建通常包括预训练、有监督微调和基于人类反馈的强化学习对齐三个阶段。预训练阶段使用大量无标注数据训练模型,以学习语言的通用特征和知识。有监督微调阶段通过特定任务的标注数据进一步调整模型参数,以适应特定应用。强化学习对齐阶段则通过人类反馈来调整模型的输出,使其更符合人类的意图和价值观。
开源与闭源大模型的差异
开源大模型由研究机构或组织提供,目的是促进学术交流和技术创新,允许全球研究者和开发者使用和贡献。闭源大模型则由商业公司持有,作为核心竞争力,通常通过API等方式提供服务,不公开模型的详细信息或代码。
大模型时代的应用开发范式
大模型时代的应用开发范式包括Prompt工程、Embedding辅助、参数高效微调等策略。这些策略旨在充分挖掘大模型的内在潜能,解决实际问题,并适应不同的应用场景和需求。
大模型应用开发的关键组成部分
大模型应用开发通常包含客户端和服务端两大部分。客户端负责接收用户请求并返回模型的响应,而服务端则负责与大模型交互,处理计算任务并生成输出。服务端可以通过直接调用API或本地部署大模型来实现。
时效性信息
在准备总结时,应当特别关注时效性信息,确保提供的内容是最新的,并且反映了当前大模型领域的研究动态和技术进展。根据最新的信息,大模型的研究正在不断深入,新的模型架构、训练方法和应用案例持续涌现。在整理上述内容时,应确保信息的准确性和完整性,同时遵循用户的指示,将知识内容进行系统的总结归纳。

